ViAdverNLI Dashboard
Vietnamese Adversarial Natural Language Inference Benchmark
Xây dựng bộ dữ liệu đối kháng tiếng Việt cho fact-checking, tạo ra các claim phức tạp để thử thách khả năng của mô hình AI.
Tạo thành công 21,262 mẫu dữ liệu đối kháng chất lượng cao với 2/3 rounds đạt Fleiss' Kappa > 0.80 (đồng thuận xuất sắc).
| Dataset | Mô tả | Số mẫu | Loại dữ liệu | Độ dài text | Phương pháp | SOTA Accuracy |
|---|---|---|---|---|---|---|
ViAdverNLI (R1-R3) Adversarial 3 rounds | benchmark NLI adversarial | ~21.3k cặp | premise/hypothesis | premise ~24 từ, hyp ~12-15 từ | human+model loop | ~58% (SOTA) |
ViNLI Baseline NLI | NLI corpus đầu tiên | >30k cặp | premise/hypothesis | premise ~24.5 từ, hyp ~18.1 từ | manual 5 annotator | ~79% (SOTA) |
ViWikiFC Wikipedia source | Wikipedia-based fact-checking | >20k cặp | claim + evidence | claim ~15-20 từ, evidence ~20-40 từ | manual FEVER style | ~79% (SOTA) |
ViFactCheck News articles | news fact-check benchmark | 7,232 cặp | claim + evidence | claim ~12-15 từ, evidence ~30-50 từ | manual expert | ~62% (SOTA) |
ISE-DSC01 Largest dataset | competition dataset | ~49.7k cặp | claim + context | claim ~10-20 từ, context ~50-100 từ | auto+manual | ~84% (SOTA) |
Độ khó cao
Mô hình SOTA chỉ đạt ~58% accuracy, thấp hơn đáng kể so với các dataset khác (~79–84%)
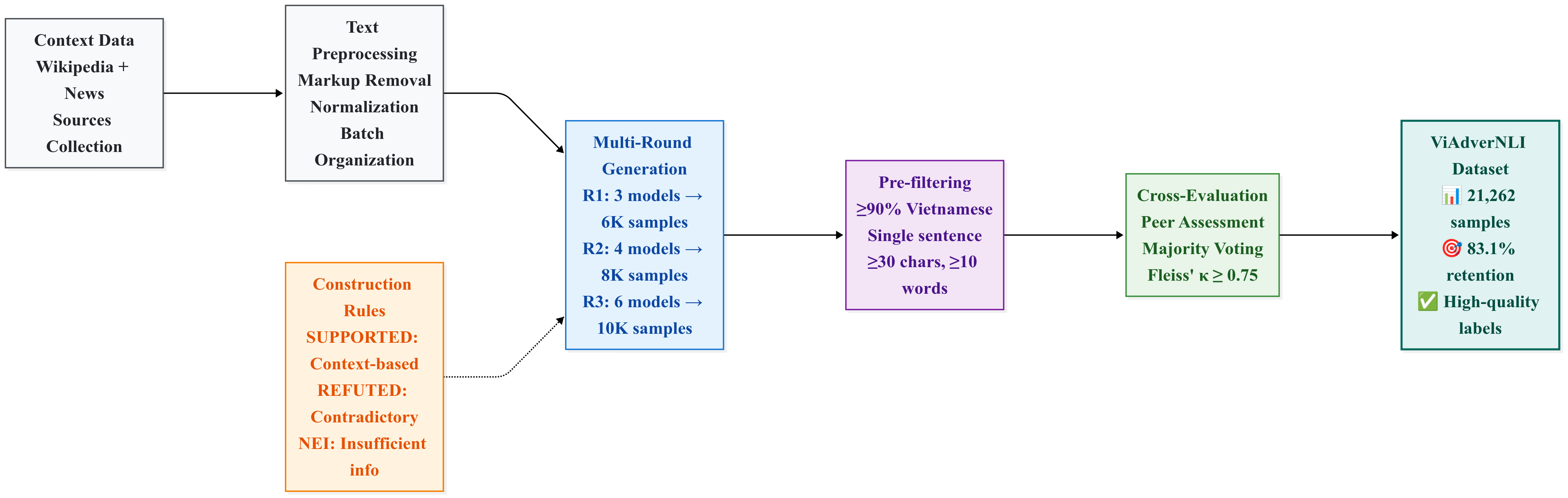
Quy trình adversarial 3 vòng
Duy nhất sử dụng human-and-model-in-the-loop để thu thập mẫu gây bẫy cho mô hình
Đa dạng ngôn ngữ
Tỷ lệ trùng từ thấp, nhiều cách diễn đạt khác biệt, bao gồm ẩn dụ, thay đổi chi tiết nhỏ
Giá trị huấn luyện
Khi huấn luyện trên ViAdverNLI, mô hình cải thiện hiệu quả tổng quát trên các dataset NLI khác
Bổ sung khoảng trống
Cung cấp benchmark NLI adversarial cho tiếng Việt, mở hướng nghiên cứu robust NLI và fact-checking
🎯 ViAdverNLI: Thử thách khó nhất
- • 58% SOTA accuracy - thấp nhất trong tất cả
- • 26% gap so với dataset dễ nhất (ISE-DSC01: 84%)
- • Adversarial design - gây khó cho mô hình SOTA
- • Human-in-the-loop - claims được crafted để đánh lừa AI
📊 Ranking độ khó:
- 1. ViAdverNLI (58%) - Cực khó 🔴
- 2. ViFactCheck (62%) - Khó 🟡
- 3. ViNLI (79%) - Trung bình 🟢
- 4. ViWikiFC (79%) - Trung bình 🟢
- 5. ISE-DSC01 (84%) - Dễ 🟢
📚 Wikipedia tiếng Việt
- • Các bài viết về khoa học, lịch sử, địa lý
- • Thông tin chính xác, đáng tin cậy
- • Đa dạng chủ đề và lĩnh vực
- • Cấu trúc tốt, dễ trích xuất thông tin
📰 Báo chí Việt Nam
- • VnExpress, Thanh Niên, Tuổi Trẻ
- • Tin tức thời sự, kinh tế, xã hội
- • Ngôn ngữ tự nhiên, gần gũi
- • Phản ánh thực tế đời sống
🎯 Tiêu chí lựa chọn Context
Chi tiết từng Round:
Dữ liệu huấn luyện:
ViNLI + ViWikiFC
Số mẫu: 5,347
Kappa: 0.8052
Dữ liệu huấn luyện:
ViNLI + ViWikiFC + ViFactCheck + ViA1
Số mẫu: 5,961
Kappa: 0.8138
Dữ liệu huấn luyện:
ViNLI + ViWikiFC + ViFactCheck + ViA1 + ViA2 + ISE-DSC01
Số mẫu: 9,954
Kappa: 0.7539
📝 General Claim Construction Rules
- Capitalize the first letter of sentences and end with proper punctuation
- Ensure correct spelling and grammar with no extra whitespace
- Use only numerical digits for dates, ages, statistics, and monetary values
- Claims must be closely related to the context content and remain on-topic
- Avoid excessive verbatim copying from context; only direct evidence citations are permitted
🚫 Additional Guidelines
- Avoid creating claims unrelated to the topic
- Avoid overusing simple transformations (only synonym replacement or negation)
- Label priority order: REFUTED > NEI > SUPPORTED
Mô hình: mBERT
Fleiss' Kappa: 0.8052
Mô hình: PhoBERT
Fleiss' Kappa: 0.8138
Mô hình: XLM-R
Fleiss' Kappa: 0.7539
© 2025 ViAdverNLI Research Team • University of Information Technology
Built with Next.js, Tailwind CSS, and Recharts